
计算机视觉作为人工智能的主流技术领域之一,历经图像分类-->目标定位-->目标检测,最终发展到图像语义分割技术。
如下图所示,从最初的识别图片信息进行单一分类,到单图片中多目标识别分析,而语义分割更是要将单图像中的度目标进行边界定位。
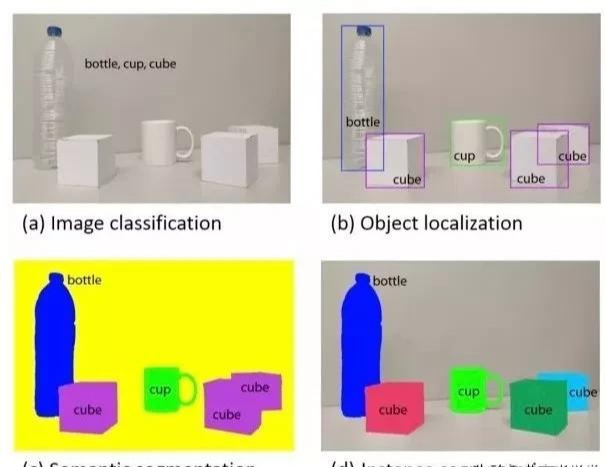
图像语义分割作为CV中重要的基本问题之一,更是CV工程师必备的基本技能,其目的是将图像分割成几组具有某种特定语义含义的像素区域,并识别出每个区域的类别,最终获得一副具有像素语义标注的图像。
在今天,图像语义分割可以说是图像理解的基石性技术,在自动驾驶系统(具体为街景识别与理解)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。
自四年前Google发布第一个版本的DeepLab模型以来,CNN特征提取器、目标尺度建模技术、语境信息处理、模型训练流程、深度学习硬件和软件的不断改进和优化。
现如今,Google最新版本DeepLab V3+已经成为各大企业CV工程师必备的语义分割技术。
为了让更多想要从事CV方向的开发工程师掌握如何这一技术模型,小编为大家准备了一本《深度学习》电子书送给大家。
微信关注公众号回复关键字“ 资料 ”即可领取。
我的微信
这是我的微信扫一扫

我的微信
我的微信公众号
我的微信公众号扫一扫

我的公众号












评论